(This is a description of a particular model, a simple Excel model I use for my own business development. I explain it, mostly in words, but with a couple of graphs and a bit of math. If you want to skip the math, feel free; I think it is understandable without. If you want the model itself, let me know, and I will send it to you, as well as explain how to use it.)
Do you network enough? Does a friend have a great opportunity for you today, an opportunity you never learn about because you have not talked to that friend in six months, and your friend never thought about you? How many opportunities are you missing every week, every month, every year, because you are not talking to people you know?
Once I worried about this myself. Was I networking enough? Was I missing opportunities? Then I built a model, and with the model both improved my networking, and set my mind at ease. Using the model, I could estimate how much opportunity I was missing. With the model, I knew I was doing more or less the right thing.
Like you, I have many people in your prefessional network, people I have worked with, and who know my work. I have more than 300 people in my network; you may have more. Neither you nor I can call all those people every day. There aren’t enough hours in the day, and in any case, we have real work to do. So networking is effectively a selection problem. Who do I call today? Who do I eat lunch with tomorrow? Who do I postpone, and talk to sometime in the future?
Suppose Joe has a perfect opportunity for me. If I talk to Joe today, he will connect that opportunity to me, tell me about it, and it becomes my lead, my prospective business partner, or my career opportunity. If I last talked with Joe 10 days ago, there is some chance he will never think about me, never connect me with the opportunity. If I last talked with Joe 20 days ago, there is a greater chance he will never think about me.
I model this gradual loss of Joe’s attention as an exponential decay. If I talk to Joe today, Joe’s contact effectiveness (for me) is 1.0. By tomorrow I will have lost some of that contact effectiveness, perhaps 1% of it, so Joe’s contact effectiveness is only 0.99. On the day after tomorrow I have lost an additional 1%, and Joe’s contact effectiveness is only 0.9801 (0.99 * 0.99). After 10 days, Joe’s effectiveness is 0.9044, and his contact value (for me) has declined in value by 9.6%.
Is 1% the right value of daily contact effectiveness loss? Or is it 0.2% or maybe 5%? 1% does seem about right. After a week, contact effectiveness is down to 93%. After a month, it’s at 74%. After three months, 40%. After six months, 16%. So the friend I have not talked with for six months might call me up out of the blue with an opportunity she heard about that fits me, but there is a 84% chance she will never think about me when she learns about the opportunity. That seems about right.
Suppose I talk with Joe fairly frequently, and Colleen less frequently. Every time I talk with Joe, his contact effectiveness bounces back to 1, then gradually declines until the next time I talk with him. Ditto for Colleen, except that her contact effectiveness goes lower, as I talk with her less often. The following chart shows Joe’s and Colleen’s contact effectiveness over time.
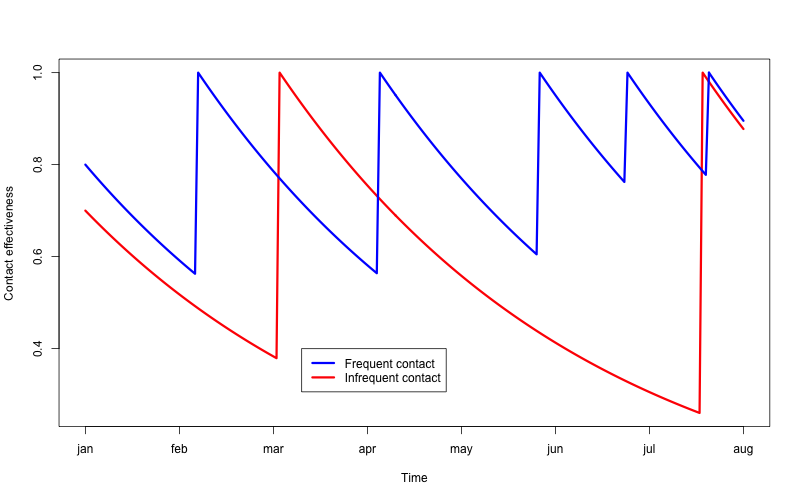
Of course the contact effectiveness of Colleen depends not just on the length of time since I last spoke with Colleen, but also on how likely she was to hear about a good opportunity for me. Not everyone is equal in this respect. Some people are connected to many others. Some are not, or at least are not connected to people who will be the source of opportunities for me.
For example, my friend and former colleague Charlie Church is a business development executive at Oracle, the software giant. He has more than 5000 linkedin contacts. He is a friendly and gregarious fellow, talking to dozens of people every day. Charlie hears about many opportunities.
At the other end of this scale is Bill Lundy. Bill is retired from the Canadian Foreign Service. After a career working issues of irregular migration—including refugees—in the major capitals of the world, Bill lives in Ottawa, doing occasional consulting projects. I feel honored to count Bill as a friend. But Bill hears about far fewer opportunities for me than Charlie does, for three reasons: because he is not connected to as many people as Charlie, because he lives in Ottawa instead of DC, and because his network is largely people in the diplomatic service.
How many more relevant opportunites does Charlie hear about, compared to Bill? I estimate about 40 times as many, that every time Bill hears about an opportunity for me, Charlie will have heard about 40.
Does the effectiveness difference between Bill’s network and Charlie’s network mean that I should never contact Bill, and just spend my limited time talking with Charlie? No. There is more to life than maximizing opportunities. I enjoy talking with Bill, and learn something new with every conversation. Also, Bill does have a leadstream for me, albeit one that does not run with the volume of Charlie’s.
Most people in my network are somewhere between Bill and Charlie, with more relevant opportunities for me than Bill, but fewer than Charlie. I score everyone in my network on a 1 to 5 scale of opportunity volume, with Charlie scored as 5 and Bill scored as 1. Opportunity volume is a log scale: someone with a score of 2 sees 2.5 times as many opportunities for me as someone with a score of 1. Someone with a score of 3 sees 6.25 times as many opportunities.
It is difficult to maintain consistency when scoring on this abstract 1 to 5 scale. Should I rate Joe as a 4 or a 5? To make consistency easier, I select five examplars, one for each value from 1 to 5. Charlie Church is my exemplar for 5; Tom Gary is my exemplar for 4. Tom sees a lot of opportunities, more than most people, but not as many as Charlie, only about 40% as many. So when I score someone new, I ask myself whether the new person is closer to Charlie, closer to Tom, or perhaps closer to my exemplar for 3, my exemplar for 2, or my exemplar for 1. Comparing people with each other makes my scoring far more consistent.
A log scale is great for scoring opportunity volume, since it reflects the wide variation in potential opportunities. But the potential value of someone wants to be expressed in a regular linear scale not a log scale. So the potential value is expressed by delogging the score, by raising the base 2.5 to the power of the score.

Why “potential value” and not just “value”? It is only potential value because I don’t talk to everyone every day. So the realized value of a contact is the potential value multiplied by the contact effectiveness, how much his effectiveness has declined due to the gap since our last contact.
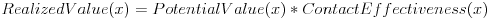
I am less interested in the value that I am realizing from Joe than in the foregone value, the potential value that I am not realizing because I have not talked with Joe recently. Every day there is some risk of opportunity loss for me, some dealflow that I never see because I am not talking with Joe. Foregone value can also be expressed in terms of potential value and contact effectiveness.
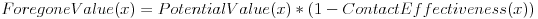
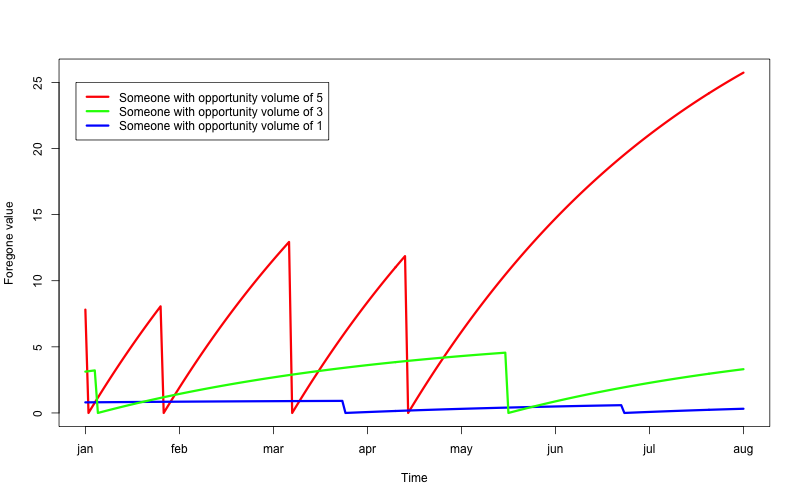
How does the foregone value change over time? It gradually increases, day by day, with no contact. Then when contact is made, it falls back down to 0, only to gradually increase again. The graph below shows the foregone value for three people, with three different opportunity volumes. The red line shows foregone value of someone with a opportunity volume of 5, contacted four times over the course of the seven months. The green line shows the foregone value of someone with an opportunity volume of 3, contacted twice over the seven months. The blue line shows the foregone value of someone with an opportunity volume of 1, also contact twice during the seven months.
People vary not just in the volume of opportunities they see, but also in how well they know my work. Someone who knows my work well is far more likely to recognize an opportunity for me when she sees it. Someone who has only a passing familiarity with my work may see an opportunity for me and never connect it to what I do.
I model this variation in work familiarity on another scale from 1 to 5, again with exemplars for each score on the scale. Someone with a work familiarity score of 5 knows my work well, and can explain it to others. Someone with a work familiarity score of 1 knows little about what I do. I score everyone in my network on this 1 to 5 scale.
As with opportunity volume, work familiary is a log scale. But work familiarity has a gentler exponent than opportunity volume. I estimate that someone who knows my work quite well—someone who has a work familiarity score of 5—is about twice as likely to recognize an opportunity for me as someone with a familiarity score of 4, twice as likely instead of 2.5 times as likely, as with opportunity volume. So someone with a score of 5 is 16 times as likely to recognize an opportunity for me as someone with a score of 1.
I score everyone on a third dimension as well, the extent to which they are inclined to assist. We all know people who go out of their way to create opportunities for us. And we all know people who may divulge an opportunity when they see one, but may not, depending on their mood. The world is a big place, with lots of different personalities. As with the other two dimensions, I score the inclination to assist of a 5 point log scale, with an even gentler exponent: 1.5.
The three dimensions result in a more nuanced potential value, one that reflects all three scores.

So what can be done with this model of potential value and foregone value? What good is it? I use it in three ways. First, every day I contact two or three people who have the highest foregone value. I talk to them about what they are seeing. Sometimes they have seen opportunities for me, sometimes not. In any case, the contact pushes their foregone value down to 0, at least for a day, until it gradually rises again.
If I only talked to the people with the most foregone value, I would never speak with many people in my network. Their foregone value would never rise high enough to break into the top 2 or 3. But I know my model is not perfect. I have certainly misscored some people on the opportunity volume, either over-estimating or under-estimating the number of opportunities they see. I have certainly misscored people on the other two dimensions as well: work familiarity and inclination to assist. Further the exponents I have estimated for these log scales are no doubt somewhat wrong. Perhaps the 2.5 exponent for opportunity volume should be a 2.2 instead, or a 3.1. Given that the model is flawed, I need to use it in a way that is not overly sensitive to its flaws.
So in addition to contacting the top two or three of foregone value, I also contact an additional one person, randomly drawing from the whole list, weighted by foregone value. Let’s look at an example. Suppose Gene has a foregone value of 700 today. And further suppose that the total foregone value of everyone across my network is 140,000 today. When I draw someone randomly from the network, weighted by foregone value, there is a chance of 700 / 140,000 that Gene will be the person drawn. Every day there’s a 0.5% chance that I will call Gene.
I use the model in a third way as well. I use it to estimate the how much total value of my network I am forgoing, by not calling everyone every day. Today, the total potential value of my network is 291,284, and the total foregone value is 144,446. So I am realizing about 50% of the value of my network, and forgoing another 50%. By making more calls every day, I could slowly bring that percentage up to 55% or perhaps even 60%. But it takes increasing effort to raise the value that I realize, more effort to raise it from 55% to 60% than it takes to raise it from 50% to 55%, and even more if I wanted to bring it to 65%. In practice, I find 50% to be a good tradeoff between the effort I care to spend networking, and the value that I want to realize from that effort.

Dave, you’ve captured a truth of business development in this model. I do have a suggestion: the rate of exponential decay varies by person according to his or her busyness. If the person is like Lucy in the Candy Factory, with change, obligations, or crises hitting her at a volume beyond digestive ability, then the need to reconnect Is more frequent than persons with a different volume. Related factors – or maybe they are symptoms – are attention span and stress. So the rate of exponential decay could perhaps be predicted, like the half time of an element, by considering the person’s situation.
No doubt. I like that image of trying to reconnect with Lucy in the candy factory.
Dave, really great system. I imagine most people are not so systematic to their detriment. I need to start building my model now :).
If you could send me the model when you have a chance I’d appreciate it.
Thanks,
Pat